JVM, память и потоки
JVM, память и потоки
JVM
★ JVM – виртуальная машина, которая загружает, интерпретирует и выполняет байт-код. Она обеспечивает платформенную независимость. Разные ОС имеют разные реализации JVM, но байт-код остаётся одинаковым.
Различные организации создают собственные реализации виртуальной машины Java, соответствующие спецификации Java Virtual Machine Specification. Основные реализации:
HotSpot — стандартная реализация от Oracle, входит в состав официального JDK. Использует адаптивную оптимизацию через JIT-компиляторы C1 (client) и C2 (server). Применяется в большинстве enterprise-приложений.
OpenJ9 — разработка компании IBM, теперь часть проекта Eclipse Foundation. Отличается низким потреблением памяти и быстрым запуском. Часто используется в облачных средах и микросервисах.
GraalVM — многоязычная виртуальная машина от Oracle Labs. Поддерживает выполнение не только Java, но и JavaScript, Python, Ruby, R, а также нативную компиляцию приложений через Native Image. Позволяет создавать standalone-исполняемые файлы без необходимости установки JVM.
Microsoft Build of OpenJDK — официальная сборка от Microsoft, оптимизированная для работы в Azure и Windows-средах. Включает поддержку современных процессорных архитектур.
Amazon Corretto — бесплатная реализация от Amazon с долгосрочной поддержкой. Оптимизирована для работы в AWS, включает патчи для повышения производительности в облачных сценариях.
Zing — коммерческая JVM от Azul Systems. Предоставляет предсказуемую задержку сборки мусора даже при работе с кучами размером в сотни гигабайт. Применяется в финансовых системах и приложениях реального времени.
Dragonwell — реализация от Alibaba, ориентированная на работу в крупных распределённых системах. Включает улучшенные алгоритмы сборки мусора и инструменты профилирования.
JIT (Just-In-Time) компилятор — это компонент JVM, который компилирует байт-код в машинный код непосредственно во время выполнения программы, а не до старта приложения. Его задача — улучшить производительность, оптимизируя код, исходя из реальных условий работы программы.
JIT компилирует только те части кода, которые реально исполняются, и может применять различные оптимизации для ускорения работы приложения.
Это позволяет сочетать гибкость интерпретируемого байт-кода и производительность нативного кода.
JIT-компилятор преобразует байт-код в машинный код во время выполнения программы. Процесс происходит поэтапно:
- Классы загружаются в память, байт-код интерпретируется.
- JVM отслеживает частоту вызова методов через счётчики профилирования.
- Методы, вызываемые часто (горячие методы), передаются компилятору уровня C1 для быстрой компиляции с минимальными оптимизациями.
- Наиболее критичные участки кода передаются компилятору уровня C2 для глубокой оптимизации: инлайнинг, удаление мёртвого кода, оптимизация циклов.
- Скомпилированный машинный код заменяет интерпретируемый байт-код в области кода (Code Cache).
- При изменении поведения программы (например, новая ветка выполнения) JVM может выполнить деоптимизацию и вернуться к интерпретации.
Пример профилирования в коде:
public class JITExample {
public static void main(String[] args) {
// Первые 10 000 вызовов интерпретируются
for (int i = 0; i < 10000; i++) {
calculate(i);
}
// Последующие вызовы выполняются как нативный код
for (int i = 10000; i < 20000; i++) {
calculate(i);
}
}
public static int calculate(int x) {
return x * x + 2 * x + 1;
}
}
Для наблюдения за работой JIT используйте флаги:
-XX:+PrintCompilation // вывод компиляции методов
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation
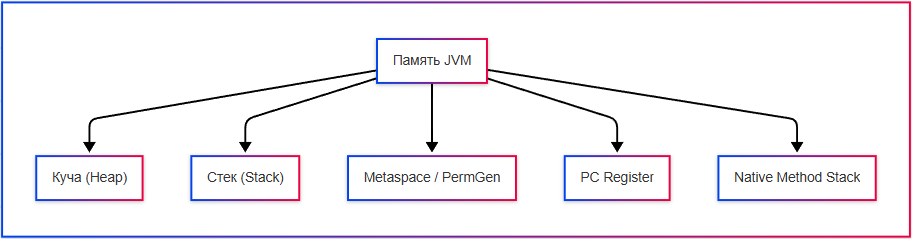
JVM делит память на несколько логических частей (областей):
- Куча (Heap) – хранение объектов Java;
- Стек (Stack) – хранение локальных переменных и вызовов методов;
- Metaspace / PermGen – хранение метаданных классов, методов, полей;
- PC Register – указывает текущую выполняемую инструкцию для каждого потока;
- Native Method Stack – для выполнения native-методов (например, C/C++).
Program Counter Register хранит адрес следующей инструкции байт-кода для выполнения в каждом потоке. Для нативных методов значение регистра не определено. PC Register — самая маленькая область памяти JVM, создаётся автоматически при старте потока.
Пример наблюдения за выполнением:
public class PCRegisterExample {
public static void main(String[] args) {
int a = 10; // инструкция 1: загрузка константы
int b = 20; // инструкция 2: загрузка константы
int c = a + b; // инструкции 3-5: сложение и сохранение
System.out.println(c);
}
}
Для просмотра байт-кода используйте javap -c PCRegisterExample.class. Каждая строка вывода соответствует значению PC Register на момент выполнения инструкции.
Native Method Stack обслуживает выполнение методов, написанных на языках низкого уровня (C, C++), вызываемых через JNI (Java Native Interface). Имеет собственную структуру, отличную от Java-стека, и управляется операционной системой.
Пример вызова нативного метода:
public class NativeExample {
// Объявление нативного метода
public native int computeNative(int x, int y);
static {
// Загрузка нативной библиотеки
System.loadLibrary("native-lib");
}
public static void main(String[] args) {
NativeExample example = new NativeExample();
int result = example.computeNative(5, 7);
System.out.println("Результат из C: " + result);
}
}
Соответствующий C-код:
#include <jni.h>
#include "NativeExample.h"
JNIEXPORT jint JNICALL Java_NativeExample_computeNative
(JNIEnv *env, jobject obj, jint x, jint y) {
return x * y + 10;
}
Куча
★ Куча – это основная область памяти для хранения объектов. Управление памятью здесь осуществляется сборщиком мусора (Garbage Collector). Куча разделена на поколения на основе гипотезы о том, что большинство объектов живут недолго.
Все объекты, созданные оператором new, размещаются в куче. Размер кучи задаётся параметрами -Xms (начальный) и -Xmx (максимальный).
Куча делится на:
- Young Generation (Eden, Survivor);
- Old Generation.
Young Generation состоит из трёх областей:
- Eden — место рождения новых объектов. При заполнении запускается Minor GC.
- Survivor Space (S0 и S1) — два пространства, используемые поочерёдно. Объекты, выжившие после Minor GC, перемещаются из Eden в одно из Survivor-пространств. При следующей сборке выжившие объекты перемещаются в другое Survivor-пространство. Возраст объекта увеличивается с каждым циклом.
Пример распределения в молодом поколении:
public class YoungGenExample {
public static void main(String[] args) {
// Объекты создаются в Eden
byte[] data1 = new byte[1024 * 100]; // 100 KB
byte[] data2 = new byte[1024 * 200]; // 200 KB
// После нескольких циклов сборки мусора
// выжившие объекты перемещаются в Survivor
for (int i = 0; i < 1000; i++) {
byte[] temp = new byte[1024 * 50];
// временные объекты быстро удаляются из Eden
}
// Объекты, пережившие несколько сборок,
// перемещаются в Old Generation
byte[] longLived = new byte[1024 * 1024 * 10]; // 10 MB
keepReference(longLived);
}
static void keepReference(byte[] data) {
// объект остаётся достижимым
}
}
Наблюдение за сборкой мусора:
java -XX:+PrintGCDetails YoungGenExample
[GC (Allocation Failure) [PSYoungGen: 51200K->1024K(56320K)] 51200K->41024K(128000K), 0.0051234 secs]
[GC (Allocation Failure) [PSYoungGen: 52224K->1024K(56320K)] 92048K->91136K(128000K), 0.0062345 secs]
[Full GC (Ergonomics) [PSYoungGen: 1024K->0K(56320K)] [ParOldGen: 91136K->82944K(87040K)] 92160K->82944K(143360K), 0.0523456 secs]
Old Generation (Tenured Generation) хранит долгоживущие объекты, пережившие несколько циклов сборки в молодом поколении. Сборка мусора здесь (Major GC или Full GC) происходит реже, но требует больше времени и останавливает все потоки приложения (stop-the-world pause).
Пример долгоживущих объектов:
public class OldGenExample {
// Статическая коллекция удерживает объекты в памяти
private static List<byte[]> cache = new ArrayList<>();
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
// Крупные объекты могут сразу попасть в Old Generation
byte[] bigObject = new byte[1024 * 1024 * 5]; // 5 MB
// Объекты, пережившие несколько сборок в Young,
// перемещаются в Old Generation
cache.add(bigObject);
// Имитация работы приложения
try { Thread.sleep(100); } catch (InterruptedException e) {}
}
}
}
Настройка размеров поколений:
-XX:NewRatio=2 // Old:Young = 2:1
-XX:SurvivorRatio=8 // Eden:Survivor = 8:1 (каждый Survivor 1/10 Young)
-Xmn512m // фиксированный размер Young Generation
Пример распределения объектов:
public class HeapExample {
public static void main(String[] args) {
// Объект String размещается в куче
String name = new String("Java");
// Массив объектов размещается в куче
Person[] people = new Person[10];
for (int i = 0; i < people.length; i++) {
people[i] = new Person("Person " + i);
}
// После выхода из метода объекты становятся кандидатами на GC
}
static class Person {
String name;
int age;
Person(String name) {
this.name = name;
this.age = 30;
}
}
}
Проверка использования памяти:
public class MemoryUsage {
public static void main(String[] args) {
Runtime runtime = Runtime.getRuntime();
long usedMemory = runtime.totalMemory() - runtime.freeMemory();
System.out.println("Используемая память: " + usedMemory / (1024 * 1024) + " MB");
// Создание множества объектов для нагрузки кучи
List<byte[]> memoryHog = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
memoryHog.add(new byte[1024 * 1024]); // 1 MB каждый
}
usedMemory = runtime.totalMemory() - runtime.freeMemory();
System.out.println("После выделения: " + usedMemory / (1024 * 1024) + " MB");
}
}
У каждого потока есть свой собственный стек фиксированного размера (по умолчанию 1 МБ на платформе x64). Стек содержит локальные переменные и вызовы методов (в виде фреймов). После выхода из метода стек автоматически очищается. К примеру, создавая метод и переменную внутри метода, переменная будет храниться в стеке.
Пример работы стека:
public class StackExample {
public static void main(String[] args) {
int x = 10; // примитив в стеке main
String s = "text"; // ссылка в стеке, объект в куче
compute(5, 3); // новый фрейм в стеке
}
static int compute(int a, int b) {
int result = a * b; // переменные в стеке compute
return add(result, 10);
}
static int add(int x, int y) {
return x + y; // фрейм add поверх фрейма compute
}
}
Переполнение стека при глубокой рекурсии:
public class StackOverflow {
public static void main(String[] args) {
recurse(0);
}
static void recurse(int depth) {
System.out.println("Глубина: " + depth);
recurse(depth + 1); // бесконечная рекурсия → StackOverflowError
}
}
Для увеличения размера стека используйте флаг -Xss2m (2 МБ на поток).
Пул строк
Пул строк — это специальная область памяти в heap, где хранятся уникальные строковые литералы. При создании строки через String s = "hello", JVM проверяет, есть ли уже такая строка в пуле. Если есть, то возвращается ссылка на существующий объект, если нет, то создаётся новый и добавляется в пул.
Это экономит память и ускоряет сравнение строк с помощью ==, так как строки из пула имеют одинаковую ссылку. Для добавления строки в пул вручную используют метод intern().
Пример работы пула строк:
public class StringPoolExample {
public static void main(String[] args) {
// Строки-литералы разделяют один объект в пуле
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // true — одна и та же ссылка
// Создание через new — новый объект в куче
String s3 = new String("hello");
String s4 = new String("hello");
System.out.println(s3 == s4); // false — разные объекты
// Принудительное добавление в пул
String s5 = s3.intern();
System.out.println(s1 == s5); // true — теперь в пуле
// Демонстрация экономии памяти
List<String> literals = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
literals.add("common-string"); // все ссылаются на один объект
}
List<String> news = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
news.add(new String("common-string")); // 10000 отдельных объектов
}
}
}
Вывод размера пула строк:
public class StringPoolStats {
public static void main(String[] args) throws Exception {
// Java 8: PermGen
// Java 9+: Metaspace
Class<?> clazz = Class.forName("java.lang.String");
Field field = clazz.getDeclaredField("value");
field.setAccessible(true);
String sample = "test";
char[] chars = (char[]) field.get(sample);
System.out.println("Размер массива символов: " + chars.length);
}
}
Metaspace
★ Metaspace заменил PermGen в Java 8+. Хранит описание классов, статические данные и методы. Располагается в native-памяти, а не в куче. В отличие от PermGen, Metaspace может динамически расширяться. Автоматически расширяется при загрузке новых классов.
Пример загрузки классов:
public class MetaspaceExample {
public static void main(String[] args) throws Exception {
// Загрузка множества динамических классов
for (int i = 0; i < 10000; i++) {
ClassLoader loader = new CustomClassLoader();
Class<?> clazz = loader.loadClass("DynamicClass" + i);
System.out.println("Загружен класс: " + clazz.getName());
}
}
static class CustomClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// Генерация байт-кода для нового класса
byte[] bytecode = generateBytecode(name);
return defineClass(name, bytecode, 0, bytecode.length);
}
private byte[] generateBytecode(String name) {
// Упрощённая генерация байт-кода
return new byte[0];
}
}
}
Мониторинг использования Metaspace:
public class MetaspaceMonitor {
public static void main(String[] args) {
MemoryPoolMXBean metaspace = ManagementFactory.getMemoryPoolMXBeans()
.stream()
.filter(pool -> pool.getName().equals("Metaspace"))
.findFirst()
.orElse(null);
if (metaspace != null) {
MemoryUsage usage = metaspace.getUsage();
System.out.println("Использовано Metaspace: " + usage.getUsed() / (1024 * 1024) + " MB");
System.out.println("Максимум: " + usage.getMax() / (1024 * 1024) + " MB");
}
}
}
Ограничение размера Metaspace: -XX:MaxMetaspaceSize=256m
PermGen (Permanent Generation) использовалась в Java 7 и ранее для хранения метаданных классов, пула строк и статических переменных. Располагалась внутри кучи Java, имела фиксированный размер (-XX:MaxPermSize), что приводило к ошибкам java.lang.OutOfMemoryError: PermGen space при динамической загрузке классов.
Пример проблемы в Java 7:
// В среде с ограниченным PermGen (Java 7)
public class PermGenLeak {
public static void main(String[] args) throws Exception {
while (true) {
// Загрузка нового класса в каждом цикле
ClassLoader loader = new URLClassLoader(new URL[]{new File("classes").toURI().toURL()});
Class<?> clazz = loader.loadClass("com.example.DynamicClass");
// loader не удаляется → утечка в PermGen
}
}
}
В Java 8 PermGen полностью заменён на Metaspace, размещённый в native-памяти с динамическим расширением.
Сборщик мусора
Java автоматически управляет выделением и освобождением памяти через сборщик мусора (Garbage Collector). Когда объект становится недостижим (нет ссылок на него), он помечается как «мусор». И GC периодически освобождает память.
Достижимость определяется наличием цепочки ссылок от GC roots (активные стеки потоков, статические поля, локальные переменные).
Пример цикла жизни объекта:
public class GCLifecycle {
public static void main(String[] args) {
// Этап 1: Создание
Person person = new Person("Alice", 30);
// Этап 2: Использование
System.out.println(person.getName());
person.setAge(31);
// Этап 3: Объект становится недостижимым
person = null;
// Этап 4: Запрос сборки мусора (не гарантирует немедленное выполнение)
System.gc();
// Финализация (устаревший механизм)
Person finalizable = new PersonWithFinalize("Bob", 25);
finalizable = null;
System.gc(); // вызовет finalize() перед удалением
}
static class Person {
private String name;
private int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
String getName() { return name; }
void setAge(int age) { this.age = age; }
}
static class PersonWithFinalize extends Person {
PersonWithFinalize(String name, int age) {
super(name, age);
}
@Override
protected void finalize() throws Throwable {
System.out.println("Финализация объекта " + getName());
super.finalize();
}
}
}
Пример утечки памяти через статическую коллекцию:
public class MemoryLeakExample {
// Статическая коллекция удерживает объекты вечно
private static List<byte[]> leak = new ArrayList<>();
public static void main(String[] args) {
while (true) {
leak.add(new byte[1024 * 1024]); // 1 MB
System.out.println("Добавлен объект, всего: " + leak.size());
try { Thread.sleep(100); } catch (InterruptedException e) {}
}
// Приведёт к OutOfMemoryError
}
}
Наблюдение за GC через JMX:
public class GCWatcher {
public static void main(String[] args) {
List<GarbageCollectorMXBean> gcBeans = ManagementFactory.getGarbageCollectorMXBeans();
for (GarbageCollectorMXBean gcBean : gcBeans) {
System.out.println("Сборщик: " + gcBean.getName());
System.out.println("Количество сборок: " + gcBean.getCollectionCount());
System.out.println("Время сборки: " + gcBean.getCollectionTime() + " ms");
}
}
}
Жизненный цикл объекта
Таким образом, объект проходит свой жизненный цикл.
Объект проходит пять этапов:
- Загрузка класса — класс загружается ClassLoader'ом, выделяется место в Metaspace.
- Создание — оператор
newвыделяет память в куче, вызывается конструктор. - Использование — объект доступен через ссылки, вызываются методы.
- Недостижимость — все ссылки на объект удалены или выходят за область видимости.
- Сборка мусора — GC обнаруживает недостижимый объект и освобождает память.
Детальный пример:
public class ObjectLifecycle {
public static void main(String[] args) {
// Этап 1: Загрузка класса Person (происходит при первом использовании)
// Этап 2: Создание объекта
Person p = new Person("John", 25);
// - выделение памяти в Eden
// - заполнение полей значениями по умолчанию
// - вызов конструктора родительского класса (Object)
// - выполнение инициализаторов полей
// - выполнение тела конструктора
// Этап 3: Использование
p.setName("Jonathan");
System.out.println(p.getName());
// Создание второй ссылки на тот же объект
Person p2 = p;
// Этап 4: Объект остаётся достижимым через p2
p = null;
// Объект становится недостижимым только после обнуления всех ссылок
p2 = null;
// Этап 5: Сборка мусора (время не определено)
System.gc(); // рекомендация JVM, не команда
// Объект с финализацией проходит дополнительный этап
Resource resource = new Resource();
resource = null;
// finalize() вызывается в отдельном потоке перед удалением
}
static class Resource {
private byte[] data = new byte[1024 * 1024];
@Override
protected void finalize() throws Throwable {
System.out.println("Ресурс освобождён");
super.finalize();
}
}
}
★ Жизненный цикл объекта:
- Создание: new Object();
- Использование: вызов методов, работа с полями;
- Неиспользуемый: нет активных ссылок;
- Кандидат на удаление: GC помечает его;
- Удалён: память освобождается.
Многопоточность
Когда выполняется какое-то действие, оно выполняется в потоке. Java поддерживает многопоточность – способность выполнять несколько потоков одновременно. Это обеспечивает повышение производительности (особенно на многоядерных процессорах), улучшение пользовательского опыта (фоновые задачи), эффективную обработку параллельных задач.
Как создать поток?
Есть два основных способа – наследование от Thread и реализация Runnable:
- Наследование от Thread:
class MyThread extends Thread {
public void run() {
System.out.println("Поток запущен");
}
}
MyThread t = new MyThread();
t.start(); // запускает новый поток
public class ThreadExample {
public static void main(String[] args) {
// Создание потока через наследование
MyThread thread1 = new MyThread("Поток-1");
MyThread thread2 = new MyThread("Поток-2");
// Запуск потоков
thread1.start();
thread2.start();
// Ожидание завершения потоков
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Все потоки завершены");
}
static class MyThread extends Thread {
private String name;
MyThread(String name) {
this.name = name;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(name + ": итерация " + i);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
break;
}
}
}
}
}
- Реализация Runnable:
class MyRunnable implements Runnable {
public void run() {
System.out.println("Поток запущен");
}
}
Thread t = new Thread(new MyRunnable());
t.start();
public class RunnableExample {
public static void main(String[] args) {
// Создание задачи
Task task1 = new Task("Задача-A");
Task task2 = new Task("Задача-B");
// Оборачивание задач в потоки
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
thread1.start();
thread2.start();
// Использование лямбда-выражения (Java 8+)
Thread lambdaThread = new Thread(() -> {
System.out.println("Поток через лямбду запущен");
for (int i = 0; i < 3; i++) {
System.out.println("Лямбда: " + i);
try { Thread.sleep(150); } catch (InterruptedException e) {}
}
});
lambdaThread.start();
}
static class Task implements Runnable {
private String name;
Task(String name) {
this.name = name;
}
@Override
public void run() {
for (int i = 0; i < 4; i++) {
System.out.println(name + " выполняет шаг " + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
}
}
Преимущества Runnable:
- Возможность наследования от другого класса
- Разделение логики задачи и механизма выполнения
- Возможность передачи одной задачи нескольким потокам
- Совместимость с пурами потоков (ExecutorService)
Предпочтительнее использовать Runnable, так как это позволяет разделить логику и поток.
Таким образом, благодаря многопоточности, мы можем использовать несколько ядер, а приложения не будут зависать во время долгих операций.
Жизненный цикл потока
Потоки тоже имеют свой жизненный цикл из состояний:
- New – создан, но ещё не запущен;
- Runnable – готов к выполнению или уже выполняется;
- Blocked / Waiting – ожидает завершения другого потока или блокировки;
- Timed Waiting – ожидает ограниченное время (например, sleep());
- Terminated – завершил работу.
New
Поток создан, но метод start() ещё не вызван.
Thread thread = new Thread(() -> {
System.out.println("Работа потока");
});
// Состояние: NEW
System.out.println(thread.getState()); // NEW
Runnable
Поток запущен (start() вызван) и готов к выполнению. Может выполняться процессором или ожидать своей очереди в планировщике ОС.
Thread thread = new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
// активная работа
}
});
thread.start();
// Состояние: RUNNABLE
System.out.println(thread.getState()); // RUNNABLE
Blocked
Поток ожидает получения монитора для входа в синхронизированный блок или метод.
public class BlockedExample {
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
synchronized (lock) {
try {
Thread.sleep(2000); // удерживает монитор 2 секунды
} catch (InterruptedException e) {}
}
});
Thread t2 = new Thread(() -> {
synchronized (lock) {
System.out.println("Получил монитор");
}
});
t1.start();
Thread.sleep(100); // дать t1 время захватить монитор
t2.start();
Thread.sleep(100);
System.out.println("Состояние t2: " + t2.getState()); // BLOCKED
}
}
Waiting
Поток ожидает неограниченное время: вызов Object.wait(), Thread.join() без таймаута, LockSupport.park().
public class WaitingExample {
public static void main(String[] args) throws InterruptedException {
Object monitor = new Object();
Thread waiter = new Thread(() -> {
synchronized (monitor) {
try {
monitor.wait(); // ожидание без таймаута
} catch (InterruptedException e) {}
}
});
waiter.start();
Thread.sleep(100);
System.out.println("Состояние: " + waiter.getState()); // WAITING
}
}
Timed Waiting
Поток ожидает ограниченное время: Thread.sleep(), Object.wait(timeout), Thread.join(timeout), LockSupport.parkNanos().
public class TimedWaitingExample {
public static void main(String[] args) throws InterruptedException {
Thread sleeper = new Thread(() -> {
try {
Thread.sleep(5000); // сон на 5 секунд
} catch (InterruptedException e) {}
});
sleeper.start();
Thread.sleep(100);
System.out.println("Состояние: " + sleeper.getState()); // TIMED_WAITING
}
}
Terminated
Поток завершил выполнение метода run() или был прерван.
public class TerminatedExample {
public static void main(String[] args) throws InterruptedException {
Thread finished = new Thread(() -> {
System.out.println("Поток завершает работу");
});
finished.start();
finished.join(); // ожидание завершения
System.out.println("Состояние: " + finished.getState()); // TERMINATED
}
}
Полный пример переходов состояний:
public class ThreadStateTransitions {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
System.out.println("1. Состояние внутри run(): " + Thread.currentThread().getState());
synchronized (this) {
try {
wait(1000); // переход в TIMED_WAITING
} catch (InterruptedException e) {}
}
System.out.println("2. После ожидания: " + Thread.currentThread().getState());
});
System.out.println("0. После создания: " + thread.getState()); // NEW
thread.start();
Thread.sleep(50);
System.out.println("3. После start(): " + thread.getState()); // RUNNABLE или TIMED_WAITING
thread.join();
System.out.println("4. После завершения: " + thread.getState()); // TERMINATED
}
}
Синхронизация
При работе с общими ресурсами могут возникнуть проблемы: гонки данных, неконсистентность состояния. Решение – синхронизация.
Синхронизированный метод:
public synchronized void increment() {
count++;
}
public class SynchronizedMethod {
private int counter = 0;
// Синхронизация на уровне экземпляра
public synchronized void increment() {
counter++;
}
// Синхронизация на уровне класса
public static synchronized void staticIncrement() {
// блокировка на классе SynchronizedMethod.class
}
public int getCounter() {
return counter;
}
public static void main(String[] args) throws InterruptedException {
SynchronizedMethod instance = new SynchronizedMethod();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) instance.increment();
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) instance.increment();
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Итоговое значение: " + instance.getCounter()); // 20000
}
}
Синхронизированный блок:
synchronized (lockObject) {
count++;
}
public class SynchronizedBlock {
private final Object lock = new Object();
private int value = 0;
public void update(int newValue) {
// Блокировка на частном объекте-замке
synchronized (lock) {
value = newValue;
}
}
public void complexOperation() {
// Блокировка на текущем экземпляре
synchronized (this) {
// критическая секция
}
}
public static void classLevelOperation() {
// Блокировка на классе
synchronized (SynchronizedBlock.class) {
// критическая секция для всего класса
}
}
}
Проблема взаимной блокировки (deadlock)
public class DeadlockExample {
private static final Object lock1 = new Object();
private static final Object lock2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (lock1) {
System.out.println("Поток 1 захватил lock1");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lock2) {
System.out.println("Поток 1 захватил lock2");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (lock2) {
System.out.println("Поток 2 захватил lock2");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lock1) {
System.out.println("Поток 2 захватил lock1");
}
}
});
t1.start();
t2.start();
// Возможна взаимная блокировка
}
}
Решение — всегда захватывать замки в одном порядке.
Синхронизировать можно класс - synchronized(MyClass.class), при этом блокировка класса влияет на все экземпляры этого класса.
А можно объект - synchronized(this).
Важно: Поток — это не процесс. Процесс имеет собственное адресное пространство, тогда как поток делит память с другими потоками. Потоки переключаются быстрее, но поток зависит от процесса.
Память
JMM
Java Memory Model (JMM) — это набор правил, определённых в спецификации языка Java, которые описывают как потоки видят изменения переменных, сделанные другими потоками, когда изменения в памяти одного потока становятся видимыми другим и в каком порядке операции чтения/записи могут быть переупорядочены (компилятором, JVM, процессором).
Пример нарушения видимости без синхронизации
public class VisibilityProblem {
private static boolean ready = false;
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
Thread writer = new Thread(() -> {
number = 42; // запись 1
ready = true; // запись 2
});
Thread reader = new Thread(() -> {
while (!ready) { // чтение 1
// активное ожидание
}
System.out.println(number); // чтение 2 — может вывести 0!
});
reader.start();
writer.start();
}
}
Без синхронизации процессор или компилятор могут переупорядочить операции, и читающий поток увидит ready = true, но не увидит обновлённое значение number.
У каждого потока есть своя локальная копия переменных (в кэше CPU или регистрах), все работают напрямую с общей оперативной памятью. Без JMM один поток может изменить переменную, а другой — никогда не увидеть это изменение, потому что читает старое значение из своего кэша. JMM решает эту проблему, давая гарантии согласованности при многопоточной работе.
Без модели памяти программы вели бы себя по-разному на разных платформах (Intel, ARM и т.д.), оптимизации компилятора могли бы сломать логику и невозможно было бы писать надёжные многопоточные приложения. JMM даёт предсказуемость: если правильно использовать synchronized, volatile, final, java.util.concurrent, то программа будет работать одинаково на всех JVM.
Видимость
Видимость (Visibility) подразумевает, что изменение переменной в одном потоке должно становиться видимым другим потокам.
// Без volatile — второй поток может никогда не увидеть изменения!
volatile boolean flag = false;
// Поток 1
flag = true;
// Поток 2
while (!flag) {
// Может выполняться вечно, если нет volatile!
}
volatile гарантирует, что запись в переменную сразу попадает в основную память, а чтение всегда идёт из основной памяти, а не из кэша.
Исправление через volatile
public class VolatileFix {
private static volatile boolean ready = false;
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
Thread writer = new Thread(() -> {
number = 42; // happens-before запись в volatile
ready = true; // volatile запись
});
Thread reader = new Thread(() -> {
while (!ready) { // volatile чтение
// активное ожидание
}
// happens-after чтение volatile — number гарантированно 42
System.out.println(number);
});
reader.start();
writer.start();
}
}
Упорядоченность
Упорядоченность (Ordering) это следующий аспект JMM. Компилятор и процессор могут переупорядочивать операции для оптимизации. Но JMM говорит: некоторые операции нельзя переставлять без потери корректности. Пример:
int a = 0;
boolean ready = false;
// Поток 1
a = 42; // 1
ready = true; // 2 ← может быть выполнено ДО 1!
// Поток 2
if (ready) {
System.out.println(a); // Может вывести 0 вместо 42!
}
Решение: использовать synchronized, volatile, или happens-before связи.
happens-before - ключевое понятие в JMM. Говорят, что операция A happens-before операции B — значит, A гарантированно видна и упорядочена перед B.
Примеры happens-before:
- Внутри одного потока: код выполняется по порядку.
- При выходе из synchronized блока → все изменения видны тому, кто войдёт в этот блок.
- Запись в volatile переменную happens-before чтения этой переменной.
- Запуск потока: действия в родительском потоке happen-before старту дочернего.
- Завершение потока: его действия happen-before .join() в другом потоке.
Это механизм, который делает многопоточный код предсказуемым.
Happens-before отношения
Встроенные happens-before связи:
public class HappensBeforeExamples {
private int x = 0;
private volatile boolean flag = false;
public void example1() {
// В пределах одного потока: порядок программы
x = 1; // A happens-before B
x = 2; // B
}
public void example2() {
// Запись в volatile happens-before чтения этой переменной
x = 10; // A
flag = true; // B (volatile запись) happens-before C
// В другом потоке:
// if (flag) { // C (volatile чтение) happens-before D
// System.out.println(x); // D — увидит 10
// }
}
public synchronized void example3() {
// Выход из synchronized блока happens-before входа другого потока
x = 20;
}
public void example4() throws InterruptedException {
Thread t = new Thread(() -> {
x = 30; // A
});
t.start(); // start() happens-before начало run() — A виден в run()
t.join(); // завершение run() happens-before возврат из join()
// x == 30 гарантированно
}
}
Пример с очередью событий
public class EventQueue {
private final List<String> events = new ArrayList<>();
private volatile boolean shutdown = false;
public void addEvent(String event) {
synchronized (events) {
if (shutdown) throw new IllegalStateException("Очередь закрыта");
events.add(event);
events.notifyAll(); // happens-before пробуждение ожидающих потоков
}
}
public String waitForEvent() throws InterruptedException {
synchronized (events) {
while (events.isEmpty() && !shutdown) {
events.wait(); // освобождает монитор, блокируется
}
return events.isEmpty() ? null : events.remove(0);
}
}
public void shutdown() {
synchronized (events) {
shutdown = true;
events.notifyAll();
}
}
}
Каждая операция notify/notifyAll создаёт happens-before связь с последующим пробуждением через wait, гарантируя видимость всех изменений, сделанных до вызова notify.
Похожий механизм есть в C# - называется он .NET Memory Model, поддерживает volatile, lock, Interlocked, MemoryBarrier. Также есть happens-before -подобные правила.